

A la hora de implementar la solución de Wazuh y los elementos que conlleva dicha solución (Elasticsearch, Kibana, Filebeat), surgen problemas de desempeño o funcionamiento de la herramienta, que impactan de manera directa o indirecta al correcto funcionamiento de la misma, por lo que cuando se presente esta situación se tengan unos pasos básicos o guía básica para solventar dicho problema, ya que a través de la documentación oficial no se expone a detalle los problemas existentes y más comunes de la solución.
Por lo que a lo largo de este blog se presentarán 4 soluciones básicas para solventar de manera efectiva problemas correspondientes a algún bug o mal desempeño de la solución Wazuh.
¿Qué es Wazuh?
Wazuh es una plataforma opensource para detección de amenazas, monitoreo de seguridad, respuesta a incidentes y cumplimiento normativo, con capacidad para monitorear servidores locales, servicios en la nube y contenedores.
https://documentation.wazuh.com/3.13/index.html
El espacio es importante
En todas las implementaciones generadas de un SIEM o un colector de eventos el espacio en disco es el que en la mayoría de los casos llega a saturarse si no se tiene una distribución de datos adecuada o una arquitectura que permita optimizar el espacio en disco.
En este caso la problemática que genera un espacio en disco lleno o en los límites del 100% de uso, provoca que la API de Wazuh deje de funcionar y esto deriva en pérdida de eventos, de igual manera el espacio en Elasticsearch si llegase a estar en los límites del 100% entra en un modo de solo lectura y deja de indexar eventos hasta que se incremente el espacio en disco o se genere una acción para remediar el espacio en disco, por lo que es importante siempre estar al pendiente de los espacios en disco con el comando df -h, el cual nos permite tener una visión del espacio restante..
Equilibrar Shards e índices
Otro de los motivos más frecuentes al momento de dar solución a problemáticas que se presenten en la solución Wazuh son los Índices generados y los shards establecidos por cada Índice, por lo que es importante el conocer la arquitectura de la solución y establecer un número de Shards por Índices con base en la misma; Asumiendo que se tiene con una arquitectura adecuada y se llega a presentar problemas con los índices lo primero es verificar el estado del cluster para comprobar que tan grave es la situación con el siguiente comando.
curl -X GET "https://[IP perteneciente a elasticsearch]:9200/_cluster/health?pretty"
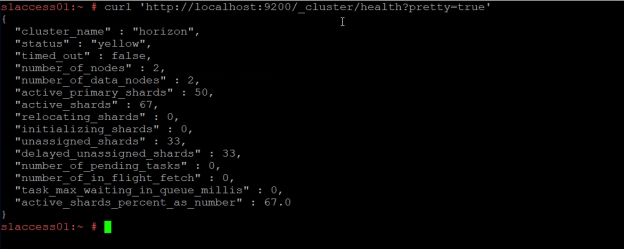
Este comando nos dará una visión general del estado del cluster de elasticsearch notificado por 3 estados: green, yellow y red.
Generalmente cuando se llegan a presentar errores con respecto a los índices y shards el estado del cluster estará en yellow o red.
Una vez realizado esta comprobación se ingresara el siguiente comando:
curl -X GET 'https://instance:9200/_cat/indices?v'
El cual nos permite identificar el estado de los índices, de igual manera estos estarán representados por green, yellow y red, además de mostrar el tamaño en disco que ocupan los índices así como los shards y réplicas generadas por índice.
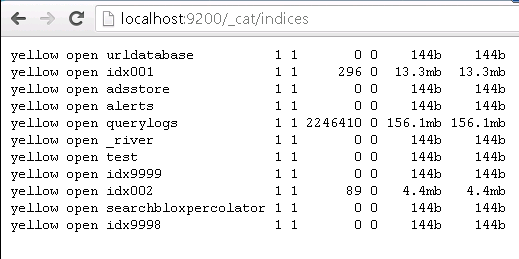
El estado correcto de un índice debe de ser Green lo cual indica que el índice está correcto y no cuenta con problema alguno, en caso de presentarse un índice en estado yellow o red esto indicara que el índice cuenta con un problema que puede llegar a ser desde una mala creación del mismo hasta involucrar una falta de espacio en disco, por lo que se recomienda en estos casos cerrar los índices que presenten problemas mediante el siguiente comando:
curl -X POST 'https://instance:9200//my_index/_close'
Nota: Al momento de cerrar los índices es importante no cerrar los índices con el caracter (.) al inicio de los mismos, ya que podría generar problemas en el cluster desde la desconfiguración del API de Wazuh hasta la pérdida de acceso a la solución.
Una vez cerrado los índices marcados en Yellow y Red es necesario reiniciar toda la solución desde el Elasticsearch, Kibana, Filebeat hasta la API del Wazuh y el Manager Wazuh.
En la mayoría de los casos que presentan errores en el estado de los índices la solución expuesta solucionara el problema, pero una vez solucionado el problema mediante este método se recomienda ampliamente validar una correcta arquitectura para en caso necesario reestructurar la solución.
Revisar los Logs
En algunas ocasiones el problema es generado por motivos “desconocidos” por lo que en este caso es necesario tener identificado las rutas donde se almacenan los logs de la solución y una vez identificado la ruta revisar el log a detalle para determinar el problema.
A continuación se presentan las rutas de los logs a revisar para determinar el problema involucrado en la solución.
La vieja confiable = Reiniciar los servicios
Aunque se vea como broma en realidad este proceso en la mayoria de los casos solventa los problemas existentes en la solución de Wazuh como se muestra en el siguiente enlace (https://github.com/wazuh/wazuh-kibana-app/issues/1016), claro que se recomienda este proceso una vez que se agotaron todas las soluciones planteadas a traves de este blog.
Conclusión
A lo largo de este blog se plantea una serie de procesos que han servido a solucionar varios problemas en ambientes de solución y al final el blog se presente como esa guia de auxilio ante imprevistos presentados en la solución, para descartar de manera eficiente y eficaz cualquier problema ya se en una etapa más robusta de cualquier implementación a través de la solución Wazuh.









